
Совсем недавно компания Google объявила о том, что для 8 языков вводит систему Neural Machine Translation (NMT) для улучшения качества перевода с помощью Google Переводчика. NMT использует машинное обучение и учитывает значение предложения в целом, выдавая в результате перевод более близкий к человеческой речи. И это круто!
Но вслед за введением NMT, специалисты Google озадачились следующим вопросом: если эта система «умеет» переводить текст с английского на корейский и наоборот, а также с английского на японский и наоборот, то сможет ли она перевести текст с корейского на японский, не делая промежуточный перевод на английский?
Для иллюстрации процесса в Google создали GIF-изображение и назвали это «zero-shot translation” (оранжевая цепь показывает zero-shot):
И оказалось, да! Система в состоянии выдать адекватный перевод между двумя никак не связанными друг с другом языками, без использования промежуточного английского.
Но вслед за этим возник еще один вопрос: если компьютер в состоянии соотнести понятия и слова формально никак не связанные, то значит ли это, что он сформировал концепцию общего смысла для этих слов, на более глубоком уровне, чем просто эквивалентные друг другу фразы?
Другими словами, создал ли компьютер свой собственный язык для понимания и представления понятий, которые он переводит с одного языка на другой?
На основании того, как связаны друг с другом различные предложения в памяти нейронной сети, исследователи из Google думают, что да.
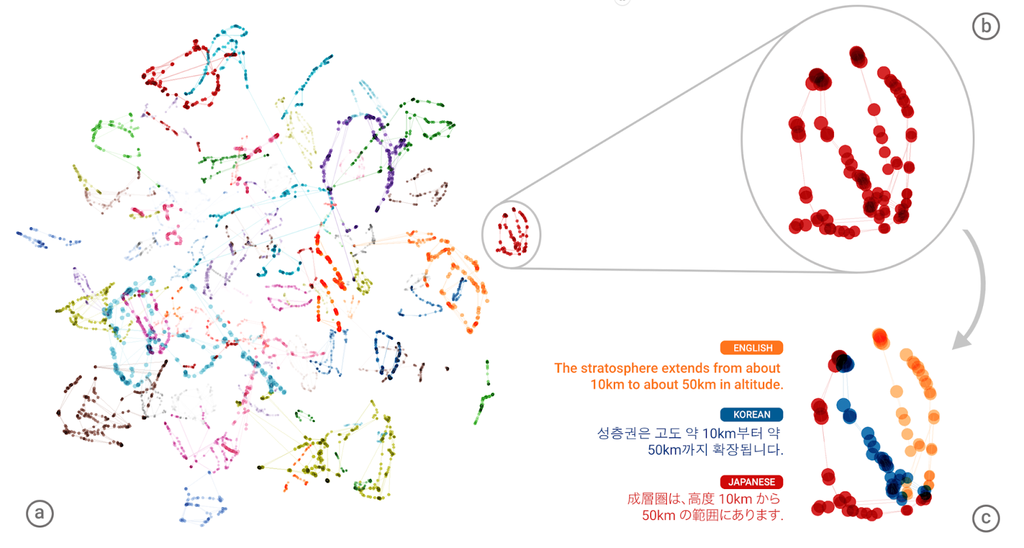
Одновременно пугает и восхищает тот факт, что искусственно созданная система может понять вещи, которым не была обучена. Как именно это происходит не знают даже люди, которые изобрели NMT, поэтому понять, каким образом система определяет сходство между предложениями на трех языках довольно сложно.
Безусловно будут проводиться и дальнейшие исследования в этой области, но если вас интересует описание работы исследователей, то его можно прочесть здесь.